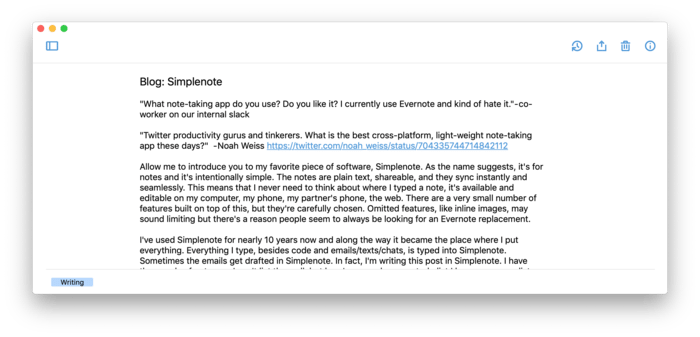
My 38-Key Layout (ZSA Voyager)

I’ve never loved the feel of mechanical keyboards, but my wrists decided it was time for me to give up my beloved Apple Magic Keyboard. Years ago, Frank at Materialize almost talked me into a Ferris Sweep with nice!nanos, but I went down a rabbit-hole of which choc color would feel most like a scissor-switch and never emerged. Then recently, I saw the ZSA Voyager, which was almost perfect1, and impulse bought it2. It arrived last Friday and I figured out my key layout over the weekend. Still taking recs for switches, but currently eyeing either the sunsets or the upcoming silent version of same.
I did all this for the better wrist position of a split keyboard, but I also got excited about putting programming symbols in a better place. Some people are delighted to incrementally tweak a layout forever, but I knew I wanted to get an initial one basically right, and then live with it...